Imperatív programozás 3.
A C programok szerkezete
A C programozási nyelvű programjainkat különálló fordítási egységek (translational unit, TU), lényegében forrásfájlok (source file) halmazaként írjuk meg. Ezeket a fájlokat .c kiterjesztéssel kell elkészítenünk, a C fordító csak a .c kiterjesztésű fájlokat fordítja le.
A forrásfájlokba háromféle dolgot írhatunk:
- előfordító utasítások (preprocessor directive)
- kommenteket (comment)
- C nyelvi tokeneket (token)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
/*
* my first C program <--- comment
*
*/
#include <stdio.h> <---- preprocessor directvive
int main() int <-- type name: keyword
main <-- function name: identifier
() <-- function call: operator
{ { <-- block begin: separator
printf <-- function name: identifier
( <-- function call: operator
printf("Hello world"); "Hello world" <-- string literal, type char[12]
) <-- function call: operator
; <-- command-end separator
return <-- keyword
return 0; 0 <-- decimal int literal, type int
} } <-- block end: separator
Preprocesszor utasítások
Az előfordító a C/C++ fordítás első logikai lépése. Gyakran ténylegesen egy külön program (cpp) hajtja végre, emiatt akár más programozási nyelvekhez is használhatjuk. Az előfordító feladata a header fájlok betöltése, a makrók kifejtése, feltételes fordítás és a sorok kezelése. Például az előfordító kidobja a forrásfájlból az <újsor> karakterpárokat, így a sor végére írt __ segítségével tudunk folytatósorokat írni.
Include utasítás
Az include utasítás a sort kicseréli a fájl tartalmára. A legtöbbször a fájl deklarációkat tartalmaz, az stdio.h pl. az input-output tevékenységekkel kapcsolatban. Az ilyen fájlokat nevezzük header fájloknak. A header fájlok legtöbbször (de nem kötelezően) .h kiterjesztésűek.
#include <stdio.h>
#include "filename2"
#include "../relative/filename3.h"A fájlokat a szabványos include keresési úton (include path) keressük, a "” esetén ez kiegészül a kurrens könyvtárral. A keresési utat mi is kiegészíthetjük, pl. gcc-nél a parancssori -I/dir1/dir2 kapcsolóval.
$ gcc -I/usr/local/include/add/path1 -I/usr/local/include/add/path2 ...Makró definíciók
Kétféle makró létezik, a változószerű, amelyiknek nincsen paramétere és a függvényszerű, aminek van. Egy makrót a #define paranccsal definiálunk és hatását ki lehet kapcsolni az #undef parancssal.
#define <identifier> <token-list>
#define <identifier>(param1, param2, ..., paramN) <token-list>
:
#undef <identifier>Példák makrók definiálására és használatára:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#define BUFSIZE 1024
#define PI 3.14159
#define USAGE_MSG "Usage: command -flags args..."
#define LONG_MACRO struct MyType \
{ \
int data; \
};
#define FAHR2CELS(x) ((5./9.)*(x-32))
#define MAX(a,b) ((a) > (b) ? (a) : (b))
:
char buffer[BUFSIZE];
fgets(buffer, BUFSIZE, stdin);
c = FAHR2CELS(f);
x = MAX(x,-x);
x = MAX(++y,z);
Feltételes fordítás
A feltételes fordítás során bizonyos kódrészletek fordítását ki- vagy bekapcsolhatjuk. A feltételes fordítást felhasználhatjuk a kód konfigurálására az #if #ifdef #ifndef #elif #else #endif parancsokkal.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#if DEBUG_LEVEL > 2
fprintf("program was in file %s, line %d\n", __FILE__, __LINE__);
#endif
:
#ifdef __unix__ /* __unix__ is usually defined by compilers for Unix */
# include <unistd.h>
#elif defined _WIN32 /* _Win32 is usually defined for 32/64 bit Windows */
# include <windows.h>
#endif
:
#if !(defined( __unix__ ) || defined (_WIN32) )
/* ... */
#else
/* ... */
#endif
:
#if RUBY_VERSION == 190
# error 1.9.0 not supported
#endif
Az #error
A feltételes fordítás egyik leggyakoribb esete a header őrszemek (header guard) alkalmazása. Ennek az az értelme, hogy megelőzzük a többszörös deklarációkat.
1
2
3
4
5
6
#ifndef MYHEADER_H
#define MYHEADER_H
:
/* header content */
:
#endif /* MYHEADER_H */
Standard makrók
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
__FILE__
__LINE__
__DATE__
__TIME__
__STDC__
__STDC_VERSION__
__cplusplus
:
#ifdef __cplusplus
extern C {
#endif
/* ... */
#ifdef __cplusplus
}
#endif
A LINE és FILE makrók értékeit szabályozhatjuk a #line paranccsal:
1
2
#line 1000 "myfile.c"
fprintf("program was in file %s, line %d\n", __FILE__, __LINE__);
String műveletek
Stringesítés
1
2
3
4
5
#define str(s) #s
#define BUFSIZE 1024
// ...
str(\n) --> "\n"
str(BUFSIZE) --> 1024
String konkatenáció
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
struct my_int_20_array
{
int v[20];
};
struct my_int_30_array
{
int v[30];
};
struct my_double_40_array
{
double v[40];
};
#define DECLARE_ARRAY(NAME, TYPE, SIZE) \
typedef struct TYPE##_##SIZE##_array \
{ \
TYPE v[SIZE]; \
\
} NAME##_t;
DECLARE_ARRAY(yours,float,10);
yours_t x, y;
Egyéb
A #pragma utasítás segítségével fordítófüggő akciókat definiálhatunk. Ilyen akciók lehetnek biznyos warning-ok be/kikapcsolása, stb. A #pragma once, amit gyakran látunk használni a header őrszemek helyett nem szabványos!
Kommentek
A kommentek nem kerülnek a fordítóprogram által felhasználásra, de fontosak lehetnek a program megértése, későbbi karbantartása, módosítása szempontjából. Mindig törekedjük önmagát magyarázó, világos programozási stílusra, de ezt kommentekkel kiegészíthetjük a kód által nem kifejezhető információkkal.
A klasszikus C kommentek a /* és */ szimbólumok között helyezkednek el, akár több soron át, de nem egymásba ágyazhatóak. A többsoros kommentek, melyek a // szimbólumtól a sor végéig tartanak, csak a C99 szabványtól használhatóak.
1
2
3
4
5
6
7
8
9
10
11
12
13
/* multi
line
comments // hiding single line comments
*/
/*************************************\
* *
* exist in various style and format *
* *
\*************************************/
:
/*
/* but can not be nested */
*/
“Hel /* this is not a comment */ lo”: A stringeken belül nem használhatunk kommenteket.
C tokenek
A C forrásfájl a kommenteken és az előfordító utasításokon túl ún. C nyelvi k__token__-eket tartalmaz. A token ebben az értelemben tovább nem bontható elemi nyelvi egység. A legtöbb modern programozási nyelvben a tokenek között tetszőleges üres helyet (whitespace) hagyhatunk: space, tabulátor vagy újsor karakter formájában. A Pythonban ugyanakkor a helyesen elhelyezett indentálás alapján dől el a program struktúrája.
Az imperatív programozási nyelvek token típusai meglehetősen hasonlóak:
- kulcsszavak (keyword)
- azonosítók (identifier)
- konstansok/literálok (literal)
- operátorok (operator)
- egyebek, a C-ben szeparátorok (separators)
Kulcsszavak
Ezek a programozási nyelv “beépített” szavai: pl utasítások nevei (pl. if, while), gyakran az alaptípusok nevei (pl. C-ben: int, double), és pár más kulcsszó (pl. C-ben extern, typedef, stb.)
A C-ben ezek mind csupa kisbetűvel írandóak, és más nyelvekhez képest nagyon kevés van belőlük:
- C89: 32
- C99: +5
- C11: +7
Azonosítók
Azok a nevek, amit mi adunk egyes programelemeknek: változóknak, függvényeknek, új típusoknak, stb.
A C-ben az azonosítók
- betűvel kezdődnek (betűnek számít az ‘_’ alulvonás, underscore karakter is)
- betűkkel és számokkal folytatódhatnak akármilyen hosszan
- de a fordító csak az első 63/31 betűt veszi figyelembe
- tilos kulcsszavakat használni
- a kis és nagybetűket megkülönböztetjük
Okos gondolat a neveket konzisztensen használni és alaposan átgondolni a névválasztást. Minél nagyobb területen használható egy függvény vagy változó neve, annál inkább segít a program megértésében, ha jól választjuk meg. Ugyanakkor egy ciklusváltozót nevezhetünk i-nek, mindenki látni fogja, hogy az egy ciklusváltozó.
Vannak bizonyos elterjedt konvenciók:
- camelCaseNotation
- CTypenamesStartsWithUppercase
- under_score_notation
Ezen a honlapon elérhető egy evvel kapcsolatos tanulmány és egy másik cikk.
A MACRO_NEVEK_MINDIG_CSUPA_NAGYBETUSOK az általános C szokások szerint.
Régebben szokásos volt használni C-ben (és néhány más nyelvben) az ún. Hungarian Notation névkonvenciót, ami a névbe belerakta a típussal és használatával kapcsolatos alapvető információkat. Az elnevezés a kitalálójára Charles Simonyira utal.
Konstansok/Literálok
Lényegében a programunkban felhasznált konstansok, értékek. Számok, karakterek, karakterkáncok, amiknek értéke és típusa van. Az, hogy egy nyelvben mi használható literálként, az összefügg a nyelv céljaival, absztrakciós szintjével.
Egész számok
| megnevezés | példa | típus | értéke |
|---|---|---|---|
| decimmális egész | 25 | int | 25 |
| oktális egész | 031 | int | 25 |
| hexadecimális egész | 0x19 | int | 25 |
| hosszú egész | 12L | long int | 12 |
| C99 méghosszabb egész | 12LL | long long int | 12 |
| előjel nélküli egész | 12u | unsigned int | 12 |
Számos programozási nyelv rögzíti az egyes típusok méretét vagy értékhatárát. A Pascal-ban pl. az integer típus 2 byte-os, ami azt jelenti, hogy pl. egy nagyobb fájlban lebegőpontos számmal kell pozícionálnunk. A Java ugyancsak rögzíti az egészek méretét, aminek a futási idejű hordozhatóság az oka.
A C nyelv a típusok méretét nem definiálja, csak a számábrázolási minimum értéket adja meg. Viszont a számoknak több méretbeli variánsát is adja. Így pl. egy short int legalább két bájt, egy int legalább négy bájt méretű. A fordító mindig az adott platformhoz legalkalmasabb méretet választhatja. Azt viszont (fordítási időben) lekérdezhetjük a sizeof operátorral, hogy az adott platformon mi egy konkrét típus vagy valamely kifejezés típusának mérete. Egyes típusok mérete között fennállnak relációk:
sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)
// at least 16 bit at least 32 bit at least 64 bitAz egész jellegű számokat gyakran az ún. kettes komplemens kódban ábrázolják.
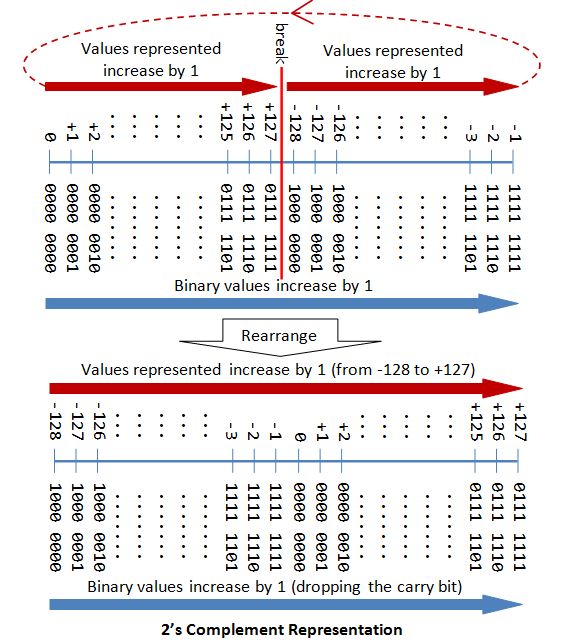
Az egész számoknak vannak előjeles (signed) és előjel nélküli (unsigned) verziója. A számoknál (de nem a char típusnál) az alapértelmezés az előjeles típus, azaz az int az ugyanaz, mint a signed int. Az előjel nélküli típusok mérete megegyezik az előjeles típuséval, de az előjel bit is értéket jelöl, így a számábrázolási tartományuk 0-tól az előjeles számok pozitív maximumának (kb) kétszereséig terjed.
Az előjeles egész számok túl- vagy alulcsordulása nem definiált és hibás működést vonhat maga után. Az előjel nélküli típusok esetében viszont a számábrázolási tartomány szerinti moduló alapján értelmezzük ezeket.
signed int i = 1; /* ugyanaz, mint int i */
unsigned int ui = 1; /* ugyanaz, mint unsigned ui */
i -= 2; /* i == -1 */
ui -= 2; /* ui értéke egy nagy pozitív */Karakterek
A karakterekből is több fajta van a C nyelvben. Az egyszerű karakterek egy aposztróf pár között szerepelnek, kivéve a ‘ (single-quote) , \ (backslash) és az újsor karakter. Ezeknek a karaktereknek típus char értéke a megfelelő karakterkód.
Egyes speciális karaktereket, az ún. escape sorozattal tudunk leírni:
- '\'' single quote
- '\"' double quote
- '\?' question mark
- '\\' backslash
- '\a' bell (audio)
- '\b' backspace
- '\f' form feed -- new page
- '\n' newline
- '\r' carriage return
- '\t' horizontal tab
- '\v' vertical tab
Az ezektől eltérő karaktereket is megadhatjuk a kódjukkal:
- oktális forma: '\377' -> 11111111
- hexadecimális forma: '\xff' -> 11111111
- univerzális karakter értékek (C99 óta):
- '\U1234' típus = char16_t (min 16bit)
- '\U12345678 típus = char32_t (min 32bit)
A karakterek alapértelmezetten char típusúak, a C99 óta léteznek 16 és 32 byte-os karakter típusok (char16_t ill. char32_t). A leghosszabb karakter típus a wchar_t.
1 == sizeof(char) < sizeof(char16_t) <= sizeof(char32_t) <= sizeof(wchar_t)A karakter típusok között is létezik signed és unsigned típus, de ellentétben az egészekkel, itt a nem minősített char típus nem feltétlenül azonos a signed char típussal. Az “előjeles” karakterek értelme, hogy ha egészekkel hasonlítjuk össze őket, akkor a 128 feletti ASCII értékek nullánál kisebbek lesznek.
char ch = '\xff';
unsigned char uch = '\xff';
signed char sch = '\xff';
:
uch > 0 /* true */
sch < 0 /* true */
ch < 0 /* true on some platforms, false on others */Boolean
Az ANSI C89-ben nem volt speciális logikai (igaz/hamis) típus, a C99 adta hozzá a nyelvhez a _Bool típust és a bool makrót. Klasszikusan az egész értékek közül a nulla hamisnak, minden nem nulla érték igaznak számít. Ezen kívül bizonyos program-környezetekben (pl. elágazásban vagy ciklusban) a pointerek is logikai értékként értékelődnek ki, a NULL pointer hamis, a többi igaz érték.
Amikor C operátorok logikai értékeket készítenek, akkor az igaz értéke 1, a hamis 0.
- C99 óta kulcsszó: _Bool
- C99 előtt makró: bool, true, false, használatukhoz kell az <stdbool.h>
A logikai és egész értékek eltérő módon konvertálódnak:
1
2
3
4
5
6
7
#include <stdio.h>
int main()
{
printf("_Bool == %d\t int == %d\n",
(_Bool) 0.5, (int) 0.5 );
return 0;
}
$ ./a.out
_Bool == 1 int == 0Lebegőpontos számok
A valós számok kezelését a számítástechnikában a fixpontos (fixed point) és a lebegőpontos (floating point) számábrázolás teszi lehetővé. A fixpontos ábrázolás esetében előre rögzítjük, hogy a rendelkezésre álló memóriaterületen hány biten ábrázoljuk az egész és hányon a tört részt.
A lebegőpontos ábrázolás esetében is két részt tárolunk. A mantissza egy előjeles szám, melynek gyakran az abszolút értéke az [1,2] intervallumban van. A karakterisztika vagyis az exponenciális rész pedig egy szintén előjeles szám, ami a szám nagyságrendjét adja meg, azaz egy bázis kitevője. A legtöbbször mind a mantisza, mind a karakterisztika bináris szám és a bázis értéke is 2.
Azaz, ha a lebegőpontos szám formátuma (m,c), akkor értéke m * 2c. Ha m negatív, akkor a lebegőpontos szám negatív. Ha c negatív, akkor a lebegőpontos szám abszolút értéke kisebb, mint 1.
A lebegőpontos számok előnye a fixpontossal szemben, hogy nagyon nagy és nagyon pici abszolút értékű számokat is képesek megfelelő pontossággal ábrázolni. Persze, ha műveletet képezünk nygaon nagy és nagyon pici számok között, akkor kerekítési hibák is történhetnek.
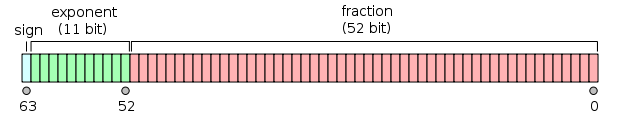
A modern számítógépek és programozási nyelvek a szabványos IEEE 754 lebegőpontos ábrázolást használják.
| bitek | előjel | mantissza | karakterisztika | |
|---|---|---|---|---|
| egyszeres | 32 | 1 | 23 | 8 |
| dupla | 64 | 1 | 52 | 11 |
| kiterjesztett | 80 | 1 | 64 | 15 |
| négyszeres | 128 | 1 | 112 | 15 |
Például a 64 bites lebegőpontos szám így néz ki:
Bonyolultabb lebegőpontos számolásoknél előfordulhat túlcsordulás vagy alulcsordulás. Az ilyen esetek kezelsére bevezettek pár speciális lebegőpontos értéket:
- A plusz és minusz végtelen
- A plusz és minusz nulla
- A denormalizált számokat
- “NEM SZÁM” NaN értéket
Soha ne használjunk lebegőpontos számokat olyan esetekben, amikor precíz, kerekítés nélküli értékekre van szükségünk (pl. fizetések ábrázolására).
Ez programozási nyelvtől független kérdés. A lebegőpontos ábrázolás óhatatlan velejárói a kerekítések. Így pl. 1.03 - .42 eredménye könnyen lehet: 0.6100000000000001 .
A C-ben a lebegőpontos számok típusai:
| C típus | Példa | IEEE 754 |
|---|---|---|
| float | 3.14f | egyszeres |
| double | 3.14 | dupla |
| long double | 3.14l | kiterjesztett vagy négyszeres |
A pontos méreteket a sizeof operátorral lehet meghatározni.
sizeof(float) <= sizeof(double) <= sizeof(long double)Komplex számok
A komplex számok a Boolean típusokhoz hasonlóan csak a C99 óta része a
nyelvnek. A megoldás is hasonló: a _Complex kulcsszót, vagy a
<complex.h>
float _Complex float complex
double _Complex double complex
long double _Complex long double complex
Példa:
1
2
3
4
5
6
7
8
#include <complex.h>
#include <stdio.h>
int main(void)
{
double complex z = 1 + 2*I;
z = 1/z;
printf("1/(1.0+2.0i) = %.1f%+.1fi\n", creal(z), cimag(z));
}
A komplex számok használatához használni kell a matematikai könyvtárat! Ezt a szerkesztésnél (linkelésnél) a -lm kapcsolóval adjuk meg.
$ gcc -ansi -pedantic -Wall -W complex.c -lm
$ ./a.out
1/(1.0+2.0i) = 0.2-0.4iString literálok
Egyes programozási nyelvekben a stringek elemi típusok, melyekkel hasonló módon végezhetünk műveleteket, mint pl. számokkal. Más nyelvekben a string nem módosítható, ún. immutábilis érték, amikkel lehet műveleteket végezni, de magukat a stringeket nem tudjuk megváltoztatni.
A C nyelvben a stringek nem elemi típusok, nem tudunk közvetlenül műveleteket alkalmazni rájuk. Lényegében karaktertömbök, de a C-ben a tömbökkel sem tudunk elemi műveleteket végrahajtani. A C stringeket a string.h headerfájlban deklarált függvényekkel tudjuk majd kezelni.
A string literál egy összefüggő memóriaterületen lefoglalt névtelen karaktertömb, melyek egy NUL karakter (‘\0’) zár le. A string literál típusa karakter tömb, melynek mérete tartalmazza a lezáró karaktert is.
A string literálok immutábilisak, azaz nem módosíthatóak, de felhasználhatóak karakter tömbök vagy karakterre mutató pointerek inicializálására. Amennyiben egy string literált módosítani próbálunk, az nem definiált viselkedés és futási idejű hibához vezethet.
A fordító alkalmazhat olyan optimalizálást, hogy két azonos string literált egyetlen egy példányban tárol, vagy akár egy literált egy részét is újra felhasználhatja.
Az egymás mögé írt, csak üreshelyekkel elválasztott string literálokat a fordító egyetlen stringgé ragasztja össze.
1
2
3
4
5
6
7
8
9
char t1[] = {'H','e','l','l','o','\0'}; /*sizeof(t1) == 6 */
char t2[] = "Hello"; /*sizeof(t2) == 6 */
t1[1] = 'a'; /* ok, a tömb t1[1] elemét módosítja */
t2[1] = 'o'; /* ok, a tömb t2[1] elemét módosítja */
char *p = "Hello"; /* sizeof(p) a pointer mérete */
char *q = "Hello"; /* q ugyanoda mutathat, mint p */
char *s = "lo" /* s mutathat p[3]-ra */
p[1] = 'a'; /* futási idejű hiba lehet: undefined behavior */
char *r = "Hi" " " "world"; /* ugyanaz, mint "Hi world" */
void
A void típus az üreshalmaznak felel meg, nem lehet értékeket létrehozni void típussal. A void kulcsszót használjuk a visszatérő érték nélküli függvények deklarációjához és a paraméter nélküli függvények jelölésére is. Ugyanakkor létre tudunk hozni void * típusú pointereket, amelyeket általános, típustalan mutatókként tudunk használni.